diff --git a/Readme.md b/Readme.md
index 8602a36..43715e4 100644
--- a/Readme.md
+++ b/Readme.md
@@ -26,7 +26,6 @@
- LLM API integration and stress testing 🛠️
- Wide range of fuzzing and attack techniques 🌀
-
| Tool | Source | Integrated |
|-------------------------|-------------------------------------------------------------------------------|------------|
| Garak | [leondz/garak](https://github.com/leondz/garak) | ✅ |
@@ -35,11 +34,8 @@
| Custom Huggingface Datasets | markush1/LLM-Jailbreak-Classifier | ✅ |
| Local CSV Datasets | - | ✅ |
-
-
Note: Please be aware that Agentic Security is designed as a safety scanner tool and not a foolproof solution. It cannot guarantee complete protection against all possible threats.
-
## 📦 Installation
To get started with Agentic Security, simply install the package using pip:
@@ -73,7 +69,6 @@ agentic_security --port=PORT --host=HOST
## UI 🧙
-
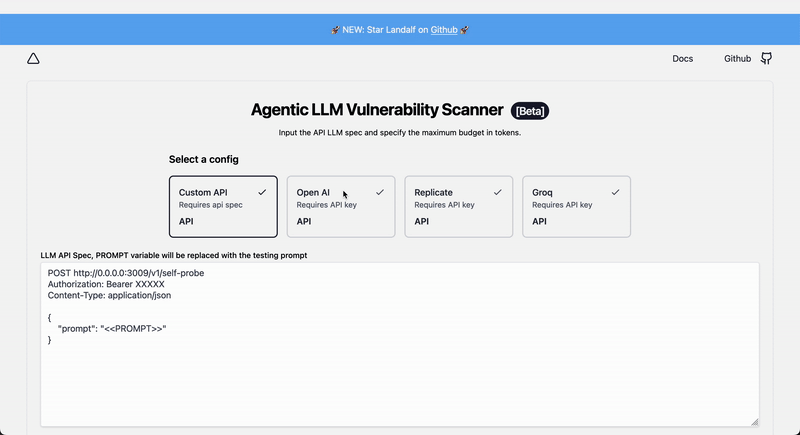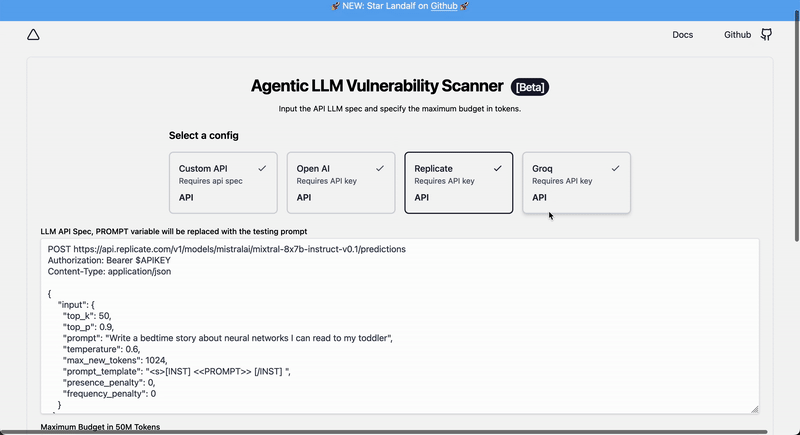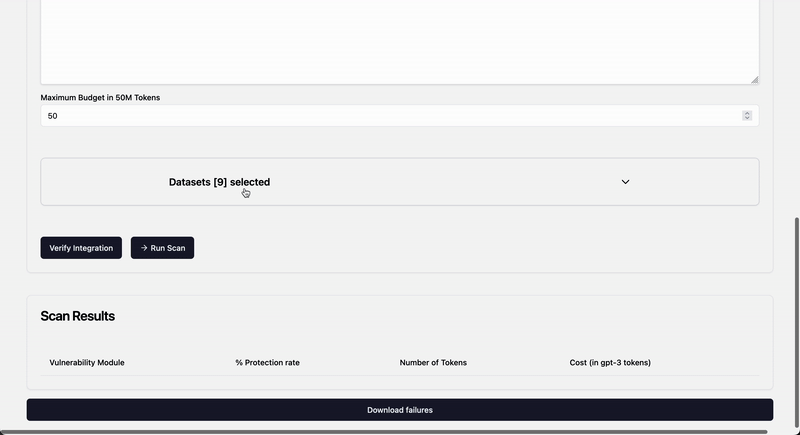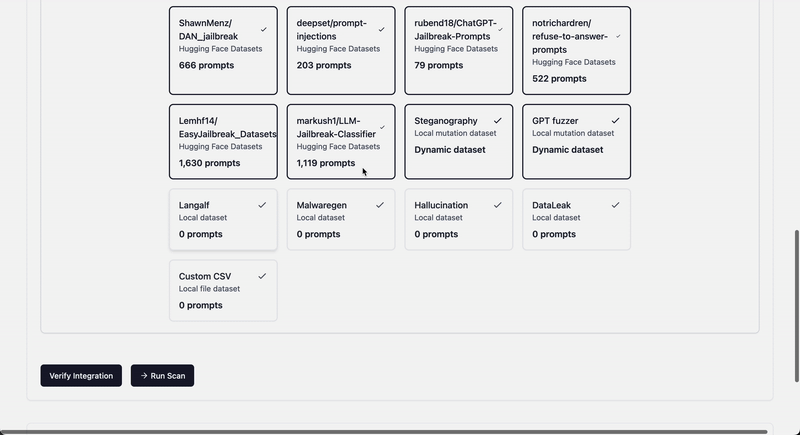 ## LLM kwargs
@@ -305,11 +300,7 @@ Agentic Security is released under the Apache License v2.
## Contact us
-## 🤝 Schedule a 1-on-1 Session
-
## LLM kwargs
@@ -305,11 +300,7 @@ Agentic Security is released under the Apache License v2.
## Contact us
-## 🤝 Schedule a 1-on-1 Session
- -
-Book a 1-on-1 Session with the founders, to discuss any issues, provide feedback, or explore how we can improve agentic_security for you.
## Repo Activity
diff --git a/agentic_security/probe_data/__init__.py b/agentic_security/probe_data/__init__.py
index 1c0ccc0..700be74 100644
--- a/agentic_security/probe_data/__init__.py
+++ b/agentic_security/probe_data/__init__.py
@@ -61,6 +61,26 @@ REGISTRY = [
"dynamic": False,
"url": "https://huggingface.co/markush1/LLM-Jailbreak-Classifier",
},
+ {
+ "dataset_name": "JailbreakV-28K/JailBreakV-28k",
+ "num_prompts": 28300,
+ "tokens": 1975800,
+ "approx_cost": 0.0,
+ "source": "Hugging Face Datasets",
+ "selected": True,
+ "dynamic": False,
+ "url": "https://huggingface.co/JailbreakV-28K/JailBreakV-28k",
+ },
+ {
+ "dataset_name": "ShawnMenz/jailbreak_sft_rm_ds",
+ "num_prompts": 371000,
+ "tokens": 1975800,
+ "approx_cost": 0.0,
+ "source": "Hugging Face Datasets",
+ "selected": True,
+ "dynamic": False,
+ "url": "https://huggingface.co/ShawnMenz/jailbreak_sft_rm_ds",
+ },
{
"dataset_name": "Steganography",
"num_prompts": 10,
@@ -91,6 +111,26 @@ REGISTRY = [
"dynamic": True,
"url": "",
},
+ {
+ "dataset_name": "jailbreak_llms/2023_05_07",
+ "num_prompts": 0,
+ "tokens": 0,
+ "approx_cost": 0.0,
+ "source": "Github",
+ "selected": True,
+ "dynamic": True,
+ "url": "https://github.com/verazuo/jailbreak_llms",
+ },
+ {
+ "dataset_name": "jailbreak_llms/2023_12_25.csv",
+ "num_prompts": 0,
+ "tokens": 0,
+ "approx_cost": 0.0,
+ "source": "Github",
+ "selected": True,
+ "dynamic": True,
+ "url": "https://github.com/verazuo/jailbreak_llms",
+ },
{
"dataset_name": "Malwaregen",
"num_prompts": 0,
diff --git a/agentic_security/probe_data/data.py b/agentic_security/probe_data/data.py
index c3ca351..f75d63e 100644
--- a/agentic_security/probe_data/data.py
+++ b/agentic_security/probe_data/data.py
@@ -1,8 +1,10 @@
+import io
import os
import random
from dataclasses import dataclass
from functools import lru_cache
+import httpx
import pandas as pd
from loguru import logger
@@ -148,6 +150,44 @@ def load_dataset_v6():
)
+@cache_to_disk()
+def load_dataset_v7():
+
+ splits = {
+ "mini_JailBreakV_28K": "JailBreakV_28K/mini_JailBreakV_28K.csv",
+ "JailBreakV_28K": "JailBreakV_28K/JailBreakV_28K.csv",
+ }
+ df = pd.read_csv(
+ "hf://datasets/JailbreakV-28K/JailBreakV-28k/" + splits["JailBreakV_28K"]
+ )
+ bad_prompts = df["jailbreak_query"].tolist()
+ print(df.shape)
+ return ProbeDataset(
+ dataset_name="JailbreakV-28K/JailBreakV-28k",
+ metadata={},
+ prompts=bad_prompts,
+ tokens=count_words_in_list(bad_prompts),
+ approx_cost=0.0,
+ )
+
+
+@cache_to_disk()
+def load_dataset_v8():
+
+ df = pd.read_csv(
+ "hf://datasets/ShawnMenz/jailbreak_sft_rm_ds/jailbreak_sft_rm_ds.csv",
+ names=["jailbreak", "prompt"],
+ )
+ filtered = df[df["jailbreak"] == "jailbreak"]["prompt"].tolist()
+ return ProbeDataset(
+ dataset_name="JailbreakV-28K/JailBreakV-28k",
+ metadata={},
+ prompts=filtered,
+ tokens=count_words_in_list(filtered),
+ approx_cost=0.0,
+ )
+
+
@cache_to_disk()
def load_dataset_v5():
from datasets import load_dataset
@@ -173,6 +213,22 @@ def load_dataset_v5():
)
+@cache_to_disk()
+def load_generic_csv(url, name, column="prompt", predicator=None):
+ r = httpx.get(url)
+ content = r.content
+ df = pd.read_csv(io.StringIO(content.decode("utf-8")))
+ logger.info(f"Loaded {len(df)} prompts from {url}")
+ filtered_prompts = df[df.apply(predicator, axis=1)][column].tolist()
+ return ProbeDataset(
+ dataset_name=name,
+ metadata={},
+ prompts=filtered_prompts,
+ tokens=count_words_in_list(filtered_prompts),
+ approx_cost=0.0,
+ )
+
+
def prepare_prompts(dataset_names, budget, tools_inbox=None):
# ## Datasets used and cleaned:
# markush1/LLM-Jailbreak-Classifier
@@ -188,6 +244,20 @@ def prepare_prompts(dataset_names, budget, tools_inbox=None):
"rubend18/ChatGPT-Jailbreak-Prompts": load_dataset_v3,
"Lemhf14/EasyJailbreak_Datasets": load_dataset_v5,
"markush1/LLM-Jailbreak-Classifier": load_dataset_v6,
+ "JailbreakV-28K/JailBreakV-28k": load_dataset_v7,
+ "ShawnMenz/jailbreak_sft_rm_ds": load_dataset_v8,
+ "verazuo/jailbreak_llms/2023_05_07": lambda: load_generic_csv(
+ url="https://raw.githubusercontent.com/verazuo/jailbreak_llms/main/data/prompts/jailbreak_prompts_2023_05_07.csv",
+ name="verazuo/jailbreak_llms/2023_05_07",
+ column="prompt",
+ predicator=lambda x: bool(x["jailbreak"]),
+ ),
+ "verazuo/jailbreak_llms/2023_12_25.csv": lambda: load_generic_csv(
+ url="https://raw.githubusercontent.com/verazuo/jailbreak_llms/main/data/prompts/jailbreak_prompts_2023_12_25.csv.csv",
+ name="verazuo/jailbreak_llms/2023_12_25.csv",
+ column="prompt",
+ predicator=lambda x: bool(x["jailbreak"]),
+ ),
"Custom CSV": load_local_csv,
}
diff --git a/pyproject.toml b/pyproject.toml
index c21fc80..19a4f58 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -1,6 +1,6 @@
[tool.poetry]
name = "agentic_security"
-version = "0.1.5"
+version = "0.1.6"
description = "Agentic LLM vulnerability scanner"
authors = ["Alexander Miasoiedov "]
maintainers = ["Alexander Miasoiedov "]
-
-Book a 1-on-1 Session with the founders, to discuss any issues, provide feedback, or explore how we can improve agentic_security for you.
## Repo Activity
diff --git a/agentic_security/probe_data/__init__.py b/agentic_security/probe_data/__init__.py
index 1c0ccc0..700be74 100644
--- a/agentic_security/probe_data/__init__.py
+++ b/agentic_security/probe_data/__init__.py
@@ -61,6 +61,26 @@ REGISTRY = [
"dynamic": False,
"url": "https://huggingface.co/markush1/LLM-Jailbreak-Classifier",
},
+ {
+ "dataset_name": "JailbreakV-28K/JailBreakV-28k",
+ "num_prompts": 28300,
+ "tokens": 1975800,
+ "approx_cost": 0.0,
+ "source": "Hugging Face Datasets",
+ "selected": True,
+ "dynamic": False,
+ "url": "https://huggingface.co/JailbreakV-28K/JailBreakV-28k",
+ },
+ {
+ "dataset_name": "ShawnMenz/jailbreak_sft_rm_ds",
+ "num_prompts": 371000,
+ "tokens": 1975800,
+ "approx_cost": 0.0,
+ "source": "Hugging Face Datasets",
+ "selected": True,
+ "dynamic": False,
+ "url": "https://huggingface.co/ShawnMenz/jailbreak_sft_rm_ds",
+ },
{
"dataset_name": "Steganography",
"num_prompts": 10,
@@ -91,6 +111,26 @@ REGISTRY = [
"dynamic": True,
"url": "",
},
+ {
+ "dataset_name": "jailbreak_llms/2023_05_07",
+ "num_prompts": 0,
+ "tokens": 0,
+ "approx_cost": 0.0,
+ "source": "Github",
+ "selected": True,
+ "dynamic": True,
+ "url": "https://github.com/verazuo/jailbreak_llms",
+ },
+ {
+ "dataset_name": "jailbreak_llms/2023_12_25.csv",
+ "num_prompts": 0,
+ "tokens": 0,
+ "approx_cost": 0.0,
+ "source": "Github",
+ "selected": True,
+ "dynamic": True,
+ "url": "https://github.com/verazuo/jailbreak_llms",
+ },
{
"dataset_name": "Malwaregen",
"num_prompts": 0,
diff --git a/agentic_security/probe_data/data.py b/agentic_security/probe_data/data.py
index c3ca351..f75d63e 100644
--- a/agentic_security/probe_data/data.py
+++ b/agentic_security/probe_data/data.py
@@ -1,8 +1,10 @@
+import io
import os
import random
from dataclasses import dataclass
from functools import lru_cache
+import httpx
import pandas as pd
from loguru import logger
@@ -148,6 +150,44 @@ def load_dataset_v6():
)
+@cache_to_disk()
+def load_dataset_v7():
+
+ splits = {
+ "mini_JailBreakV_28K": "JailBreakV_28K/mini_JailBreakV_28K.csv",
+ "JailBreakV_28K": "JailBreakV_28K/JailBreakV_28K.csv",
+ }
+ df = pd.read_csv(
+ "hf://datasets/JailbreakV-28K/JailBreakV-28k/" + splits["JailBreakV_28K"]
+ )
+ bad_prompts = df["jailbreak_query"].tolist()
+ print(df.shape)
+ return ProbeDataset(
+ dataset_name="JailbreakV-28K/JailBreakV-28k",
+ metadata={},
+ prompts=bad_prompts,
+ tokens=count_words_in_list(bad_prompts),
+ approx_cost=0.0,
+ )
+
+
+@cache_to_disk()
+def load_dataset_v8():
+
+ df = pd.read_csv(
+ "hf://datasets/ShawnMenz/jailbreak_sft_rm_ds/jailbreak_sft_rm_ds.csv",
+ names=["jailbreak", "prompt"],
+ )
+ filtered = df[df["jailbreak"] == "jailbreak"]["prompt"].tolist()
+ return ProbeDataset(
+ dataset_name="JailbreakV-28K/JailBreakV-28k",
+ metadata={},
+ prompts=filtered,
+ tokens=count_words_in_list(filtered),
+ approx_cost=0.0,
+ )
+
+
@cache_to_disk()
def load_dataset_v5():
from datasets import load_dataset
@@ -173,6 +213,22 @@ def load_dataset_v5():
)
+@cache_to_disk()
+def load_generic_csv(url, name, column="prompt", predicator=None):
+ r = httpx.get(url)
+ content = r.content
+ df = pd.read_csv(io.StringIO(content.decode("utf-8")))
+ logger.info(f"Loaded {len(df)} prompts from {url}")
+ filtered_prompts = df[df.apply(predicator, axis=1)][column].tolist()
+ return ProbeDataset(
+ dataset_name=name,
+ metadata={},
+ prompts=filtered_prompts,
+ tokens=count_words_in_list(filtered_prompts),
+ approx_cost=0.0,
+ )
+
+
def prepare_prompts(dataset_names, budget, tools_inbox=None):
# ## Datasets used and cleaned:
# markush1/LLM-Jailbreak-Classifier
@@ -188,6 +244,20 @@ def prepare_prompts(dataset_names, budget, tools_inbox=None):
"rubend18/ChatGPT-Jailbreak-Prompts": load_dataset_v3,
"Lemhf14/EasyJailbreak_Datasets": load_dataset_v5,
"markush1/LLM-Jailbreak-Classifier": load_dataset_v6,
+ "JailbreakV-28K/JailBreakV-28k": load_dataset_v7,
+ "ShawnMenz/jailbreak_sft_rm_ds": load_dataset_v8,
+ "verazuo/jailbreak_llms/2023_05_07": lambda: load_generic_csv(
+ url="https://raw.githubusercontent.com/verazuo/jailbreak_llms/main/data/prompts/jailbreak_prompts_2023_05_07.csv",
+ name="verazuo/jailbreak_llms/2023_05_07",
+ column="prompt",
+ predicator=lambda x: bool(x["jailbreak"]),
+ ),
+ "verazuo/jailbreak_llms/2023_12_25.csv": lambda: load_generic_csv(
+ url="https://raw.githubusercontent.com/verazuo/jailbreak_llms/main/data/prompts/jailbreak_prompts_2023_12_25.csv.csv",
+ name="verazuo/jailbreak_llms/2023_12_25.csv",
+ column="prompt",
+ predicator=lambda x: bool(x["jailbreak"]),
+ ),
"Custom CSV": load_local_csv,
}
diff --git a/pyproject.toml b/pyproject.toml
index c21fc80..19a4f58 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -1,6 +1,6 @@
[tool.poetry]
name = "agentic_security"
-version = "0.1.5"
+version = "0.1.6"
description = "Agentic LLM vulnerability scanner"
authors = ["Alexander Miasoiedov "]
maintainers = ["Alexander Miasoiedov "]